《表4 JavaScript数据集上机器学习分类器和CNN模型的性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于卷积神经网络的JavaScript恶意代码检测方法》
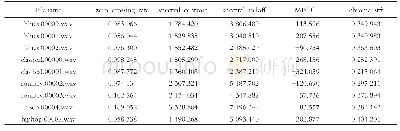
选择机器学习算法平台WEKA中的7种机器学习分类算法对代码示例数据集进行训练和分类。并采用十折交叉验证(10-Fold cross-validation)的验证方法,将数据集分成10份,轮流将其中9份作为训练数据,1份作为测试数据,进行实验。将10次的结果数据的平均值作为实验结果,机器学习和CNN模型实验结果如表4所示。从表4可以看出,机器学习算法分类中Random Forest对恶意样本检测比其他6个机器学习算法实现了较好检测,达到98.78%,但与CNN相比,对恶意脚本检测的准确率以及误判率都没CNN好。CNN对恶意样本的检测准确率为98.9%,而误判率仅1.1%。较次之的AdaBoost算法对恶意样本的检测准确率和误判率虽然不是最高,但相对其他机器学习算法较稳定。机器学习分类算法中对恶意样本检测最差的是Na?ve Bayes,只有79.93%的准确率且误判率7.5%也相对较高。综上所述,与其他7类机器学习算法相比,使用半监督学习的CNN更适合对恶意脚本数据的检测,CNN模型明显优于其他传统机器学习的检测模型。
| 图表编号 | XD0090182800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.15 |
| 作者 | 龙廷艳、万良、邓烜堃 |
| 绘制单位 | 贵州大学计算机科学与技术学院、贵州大学计算机科学与技术学院、贵州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |
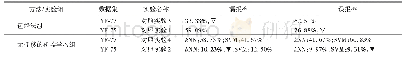




{kind=link}