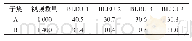
《表1 BLEU分值:大规模连续中国手语数据集的创建与分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
使用上述方法对数据集中两个随机选择的子集进行基础实验。每个视频以240帧的等距采样来表示,然后从每帧中提取骨骼、像素、面部和姿态特征。使用jieba分词工具来标注普通话的句子。每个句子都会被分成几个短语,这些短语都是汉语普通话中经常会使用到的。为了评估预测文本和真实文本之间差异的性能,使用BLEU分数,即根据被切分的单词和短语的相似性计算而来,如表1所示。发现身体和手部骨骼、身体矢量和面部特征结合起来的预测效果是最好的。
| 图表编号 | XD0067426200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 袁甜甜、赵伟、杨学、胡彬 |
| 绘制单位 | 天津理工大学聋人工学院、天津理工大学聋人工学院、天津理工大学聋人工学院、天津理工大学聋人工学院 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}