《表1 数据集的规模和含义》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于数据挖掘和RandomForest算法的助学金分类研究》
文章所有数据来源于数据城堡某高校一卡通两年的脱敏数据集。数据集包含消费行为数据、图书馆门禁数据、寝室门禁数据、助学金分类数据、学生成绩排名数据以及图书馆借阅数据等测试集和训练集分别6个,共计12个文本数据集(见表1)。由于test数据集没有分类标签,而实际的分类标签又未知,不能进行数据测试集的拟合优度和泛化能力的测量,所以助学金模型的数据完全基于训练集的数据,同时采用交叉验证进行模型训练。预留30%的数据用于测试。
| 图表编号 | XD0040007200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.28 |
| 作者 | 王雨萌、武小军、罗雅晨 |
| 绘制单位 | 同济大学、同济大学、同济大学 |
| 更多格式 | 高清、无水印(增值服务) |

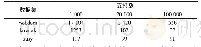


{kind=link}