《表3 不同支持度下各数据集的F-list规模》
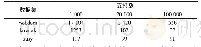 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于MapReduce的并行频繁项集挖掘算法研究》
为验证PFIMD算法的挖掘效果,本文将PFIMD算法分别与PFP-Growth[11]、LBPFP[14]、MREclat[17]、SPEclat[18]和MRPrePost算法[19]进行了对比。在执行上述并行算法时需要根据每个数据集的F-list规模设置分组数目,表3给出三种数据集在不同支持数下F-list数目的具体情况。根据F-list大小对于susy数据集设置分组数为50组,kosarak数据集设置分组数为100组,webdocs数据集设置分组数为1 000组,分别在上述三个数据集上运行六种并行算法,实验结果如图2所示。
| 图表编号 | XD00202147500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.05 |
| 作者 | 刘卫明、张弛、毛伊敏 |
| 绘制单位 | 江西理工大学信息工程学院、江西理工大学信息工程学院、江西理工大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}