《表1 不同稀疏度下各推荐算法比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为进一步确定优化效果,将稀疏度改变。稀疏度定义为用户评分数据中未评分项所占比例,即为:1–评分项/(用户数×电影数)。在本文采用的数据集中,用户有943人,电影有1 682部,原始数据记录有90 570条,即稀疏度d为:d=1–90 570/(943×1 682)=0.943。再随机抽取45 542、36 481、27 245、18 097条记录作为测试数据,相应稀疏度为0.971、0.977、0.983、0.989。从图1看出:在支持度权重[15–16]优化算法中k取值范围在15~30之间具有更好的优化效果;在邓爱林等[14]优化算法中,k取值范围在10~25之间具有更好的优化效果。基于计算量考虑,本文采用k=15进行实验。支持度权重[15–16]优化算法、邓爱林等[14]优化算法和本文优化算法的MAE在稀疏度增大情况下的比较结果如表1所示。
| 图表编号 | XD00122402800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.20 |
| 作者 | 岳希、唐聃、舒红平、安义文 |
| 绘制单位 | 成都信息工程大学软件工程学院、软件自动生成与智能服务四川省重点实验室、成都信息工程大学软件工程学院、软件自动生成与智能服务四川省重点实验室、成都信息工程大学软件工程学院、软件自动生成与智能服务四川省重点实验室、成都信息工程大学软件工程学院 |
| 更多格式 | 高清、无水印(增值服务) |


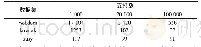



{kind=link}