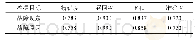
《表5 文本调序实验评估:连续手语识别中的文本纠正和补全方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
单位:%
本次文本调序实验分别对Bi-gram、Tri-gram、4-gram、5-gram模型进行对比验证,设置集束宽度为20。文本调序的实验结果如表5所示,只基于规则转换绝对正确率达68.60%,表明转换规则已经可以正确处理多数语句;此外,从Bi-gram到4-gram,随着上下文的依赖增长,各项指标均有所上升,说明上下文信息有助于调整语句结构。根据理论基础,在N-gram模型中,N越大,实验结果应越好,但基于5-gram模型的指标却不升反降。这是由于平均每条测试语句的词汇约为4.9个,当N≥5时,依据N-gram原理,在训练语料有限的条件下,每条测试语句组成的N元词序列频度在训练好的N元词表中将会随着N的增大而减小,由此会影响模型的整体性能。此外,实验结果也表明,仅训练50万条语料,4-gram的模型大小和训练时长均约为Tri-gram的2倍。因此,对于小规模短序列数据集,并不是N越大,模型效果越好,需视情况择优选择。
| 图表编号 | XD00201808400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.10 |
| 作者 | 龙广玉、陈益强、邢云冰 |
| 绘制单位 | 湘潭大学计算机学院·网络空间安全学院、湘潭大学计算机学院·网络空间安全学院、中国科学院计算技术研究所、中国科学院计算技术研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}