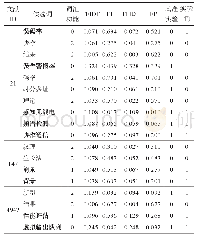
《表7 量词标注实验评估:连续手语识别中的文本纠正和补全方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
单位:%
量词定位和补全的实验结果如表7所示,实验结果表明LSTM模型综合指标最低,Bi-LSTM的综合指标优于其他模型。HMM是统计模型,其对转移概率和表现概率直接建模,统计共现概率。在该量词定位实验中,量词位置具有明显的特征,例如量词通常跟在数词或代词后,并且每个量词有相对固定的搭配如“一条狗,一只鱼”,HMM能很好地提取这一信息。而LSTM虽能捕获长距离依赖,但其只能提取上文信息特征,无法利用下文信息特征,序列的特征抽取不够充分,因此标注效果不理想。相比之下,Bi-LSTM解决了LSTM的问题,又得益于非线性的建模,所以取得更好的结果。另外,根据文献[14]可知,Bi-LSTM+CRF作为目前主流的序列标注模型,其实验结果应优于Bi-LSTM,而本次实验训练数据为低维时序数据,且样本量相对较小,这是造成Bi-LSTM+CRF性能稍次于Bi-LSTM的主要原因。
| 图表编号 | XD00201808700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.10 |
| 作者 | 龙广玉、陈益强、邢云冰 |
| 绘制单位 | 湘潭大学计算机学院·网络空间安全学院、湘潭大学计算机学院·网络空间安全学院、中国科学院计算技术研究所、中国科学院计算技术研究所 |
| 更多格式 | 高清、无水印(增值服务) |
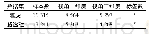




{kind=link}