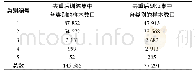
《表1 训练集样本和测试集样本划分结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Wasserstein GAN的新一代人工智能小样本数据增强方法——以生物领域癌症分期数据为例》
在本研究中,作为实验数据的血清样本由同济医院(华中科技大学同济医学院)提供。首先通过肽N-糖苷酶F(PNGase F)切断糖链与天冬酰氨间的糖肽键,从人血清糖蛋白中特异性释放N-聚糖[68]。然后进行全甲基化修饰,并通过MALDI 4800(AB SCIEX,Concord,Canada)进行质谱检测,得到样本中N-聚糖质荷比(m/z)在质谱上峰的分布及相对含量,如图3所示。最后,使用Data Explorer4.5对得到的质谱数据进行处理,并生成包含m/z值与质谱强度(参照美国信息交换标准代码对照光谱)的.txt文件。癌症分期按照肿瘤TNM(tumor node metastasis)分期系统进行划分。通过上述生物学过程,获得60个肝癌样本(TNM I期21个、TNM II期24个、TNM III期15个)和作为对照组的18个健康样本。其中每个肝癌样本包含42个特征,每个样本根据其峰值分布及相对强度可表示为一个42维的特征向量(图3)。将所有肝癌分期原始样本分别按照60%和40%的比例划分为训练集样本和测试集样本,划分结果如表1所示。
| 图表编号 | XD0061019000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.01 |
| 作者 | 刘宇飞、周源、刘欣、董放、王畅、王子鸿 |
| 绘制单位 | College of Life Science and Technology,Huazhong University of Science and Technology、School of Public Policy and Management,Tsinghua University、Center for Strategic Studies,Chinese Academy of Engineering、School of Public Policy and Management,Tsinghua Uni |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}