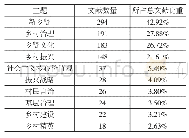
《表2 每个主题对应的频率最大的10个主题词》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由于沿线国家社会发展态势存在差异,新闻主题类型不完全相同,因此,本文利用LDA主题模型针对各沿线国家新闻数据分别进行主题挖掘,得到每条新闻的主题概率向量;然后引入K均值聚类算法对主题概率向量进行划分,若向量值不足以划分为3类,或最大概率值小于阈值(阈值大小与主题挖掘时设定的主题数目有关),或各聚类簇中心差异过小,则认为此新闻文档无法对应于任一主题,丢弃此新闻文档。最后将最大概率值对应聚类簇中的主题作为新闻文档的主题,分析各主题的主题词概率向量,对主题进行人工解释,共得到19类感兴趣的新闻主题,各主题概率最大的10个主题词如表2所示。对沿线国家新闻主题进行统计,计算得到各类新闻主题占各国新闻总数的百分比(表3)。以沿线25个国家的省一级的行政单元为单位,统计各类新闻主题出现的频率,得到各省新闻主题频率向量,将占比最高的新闻主题作为地区的社会关键要素,对此结果进行时空可视化,如图1所示。
| 图表编号 | XD0056136200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.28 |
| 作者 | 马明清、袁武、葛全胜、袁文、杨林生、李汉青、李萌 |
| 绘制单位 | 中国科学院地理科学与资源研究所、中国科学院大学、北京理工大学计算机学院、中国科学院地理科学与资源研究所、中国科学院地理科学与资源研究所、中国科学院地理科学与资源研究所、中国公安部第一研究所、中国科学院地理科学与资源研究所、中国科学院大学 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}