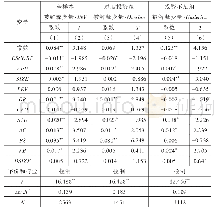
《表5 汉盲转换准确率 (不考虑标调) (%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
汉盲转换的实验结果如表5和表6所示。可以看出,无论是考虑标调还是不考虑标调,对于所有领域,基于汉盲对照语料库的MLP模型和LSTM模型效果均优于采用纯盲文语料库的方法(文献[16]系统),LSTM模型的结果优于MLP模型,由此可以看出采用汉盲对照语料库和更复杂的机器学习模型的重要性。在不考虑标调时,本文提出的基于汉盲对照语料库和深度学习的分词算法可达到94.42%的准确率,已经达到实用水平。从各领域来看,科学科普的准确率最高,但这可能是由于训练语料和测试语料来自同一套丛书相似性较高造成的。而医学领域性能相对较低,这可能是因为其中与中医相关的测试语料包含一定的古文内容和中医专用词汇,而训练语料主要为现代汉语,只有一部分为医学领域语料,总量规模不是很大,导致训练尚不充分。
| 图表编号 | XD0054887400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 蔡佳、王向东、唐李真、崔晓娟、刘宏、钱跃良 |
| 绘制单位 | 中国科学院计算技术研究所移动计算与新型终端北京市重点实验室、中国科学院大学、中国科学院计算技术研究所移动计算与新型终端北京市重点实验室、中国盲文出版社、中国科学院计算技术研究所移动计算与新型终端北京市重点实验室、中国科学院大学、中国科学院计算技术研究所移动计算与新型终端北京市重点实验室、中国科学院计算技术研究所移动计算与新型终端北京市重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}