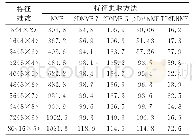
《Table 1 CTR based on different feature extraction methods表1基于不同特征提取方法的点击率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《融合协同过滤与上下文信息的Bandits推荐算法》
常用的商品特征提取方法还包括矩阵分解,如之前所述,该方法仅利用了用户对商品的评分或0-1反馈,而引入自然语言处理中的主题模型可以挖掘商品评价信息进而构建商品潜在特征,常用的方法有TF-IDF(term frequency-inverse document frequency)、LDA模型。表1对比了通过以上三种方法提取商品特征后,基于本文COFIBA算法推荐并迭代10 000次时的CTR,其中LDA_0.5代表仅利用50%的评价文本训练商品特征。实验结果表明,在两数据集上,基于文本主题提取方法TF-IDF、LDA能得到更高的点击率,因为其利用了信息量更大的商品评价文本,能够更加准确地表征商品特征,其中LDA的效果更佳。此外,当仅用一半的文本训练LDA模型时,CTR会急剧下降,因此在实际运用中,商品的评价信息越丰富,提取到的特征表征效果越好。
| 图表编号 | XD0054141600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.01 |
| 作者 | 王宇琛、王宝亮、侯永宏 |
| 绘制单位 | 天津大学电气自动化与信息工程学院、天津大学电气自动化与信息工程学院、天津大学电气自动化与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}