《表5 迭代次数:基于特征融合的中文简历解析方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:Pre(Cn)表示用中文维基百科(Cnwiki)语料库训练的词向量;Dr表示使用Dropout。
由表4的实验优化结果可知,对模型进行优化,然后再对中文文本简历进行标注解析的效果要优于未对模型优化的效果。在训练模型的时候加入Dropout,其模型的F1值比未加入Dropout的F1值高0.52%,其主要原因在于BLSTM-CRF模型比较复杂,权重参数多,学习能力强,但是容易出现过拟合。而加入Dropout之后,在对模型的权值进行更新时,隐含节点以一定概率随机出现,这样权值的更新就不再依赖有固定关系的隐含节点共同作用,阻止了某些特征仅仅在其特定特征下才有效果的情况,在一定程度上提高了模型对简历解析的效果。此外,由表4和表5的实验结果还发现,在加入Dropout的基础上加入预先训练好的大规模无标签的词向量表去初始化模型中的词向量表,模型的训练速度和精确度也会有一定的提升。加入预先训练词向量的模型在第67次迭代时,性能达到了最优,比未加入预先训练词向量的模型少迭代21次;其次,模型的F1值在原来Dropout的基础提升了将近2%。
| 图表编号 | XD0053259500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.15 |
| 作者 | 陈毅、符磊、代云霞、张剑 |
| 绘制单位 | 重庆邮电大学光通信与网络重点实验室、北京大学深圳研究院、深港产学研基地深圳市智能媒体和语音重点实验室、安徽大学计算机智能与信号处理教育部重点实验室、北京大学深圳研究院、深港产学研基地深圳市智能媒体和语音重点实验室、重庆邮电大学光通信与网络重点实验室、北京大学深圳研究院、深港产学研基地深圳市智能媒体和语音重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |

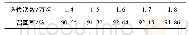


{kind=link}