《表1 基于改进TF-IDF特征权重分类算法自动分类POI的混淆矩阵》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
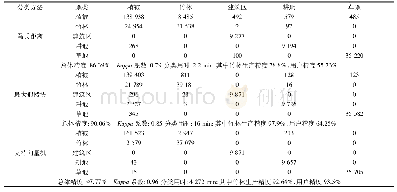
本文共选取了中国POI数据网提供的25 976个已分类POI作为总样本,类别包括餐饮、购物、交通设施、教育、金融、医疗和政府机构。将POI数据集分成两个子集:一个用于训练改进TF-IDF分类器,即训练集;另一个用于对分类器进行评估测试,即测试集。从总样本中随机抽取20 784个POI作为训练集,其中各类样本容量为:餐饮6376个、购物4941个、交通设施2723个、教育1881个、金融1992个、医疗1411个、政府机构1460个。其余5192个POI作为测试集。针对POI的短文本特征,本文选用了由哈尔滨工业大学信息检索实验室扩展和维护的《同义词词林》对文本特征进行扩展。该《同义词词林》每条词条中的词语语义相同或具有很强的相关性,所有收录到的词条按照树状的层次结构组织到一起。结果(见表1)表明,基于改进TF-IDF的方法实现的POI自动分类,其分类精度达到83%。
| 图表编号 | XD0052959200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.25 |
| 作者 | 范海林、梁明、李佳、段平、王姗姗、王彤 |
| 绘制单位 | 广东绘宇智能勘测科技有限公司、安徽大学资源与环境工程学院、云南师范大学旅游与地理科学学院、云南师范大学旅游与地理科学学院、安徽大学资源与环境工程学院、安徽大学资源与环境工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}