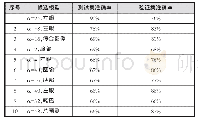
《表6 候选模型在验证数据集上的准确率 (%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《人工智能视域下的学习参与度识别方法研究——基于一项多模态数据融合的深度学习实验分析》
经过分析,主要的原因应是验证集和测试集的数据分布不一致。模型选择依赖于验证集,如果验证集与测试集的数据分布差异太大,则会直接影响模型在测试集上的准确率。我们搜索在测试集上准确率最高的模型,具体如表6所示。其中“α=48,总预测”一项为实验中选出的最佳模型,在测试集上的准确率仅排在第10位;而“α=24,左眼”则以非常高的准确率(90.6%)排在第1位。这说明,虽然本实验所选取的验证集和测试集分别在性别和参与度级别方面都较为平衡,但是仍然有性别、参与度级别以外的其它未知因素,影响其数据分布规律,其中可能的因素包括被试的表情习惯、行为习惯等。
| 图表编号 | XD0045271800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.20 |
| 作者 | 曹晓明、张永和、潘萌、朱姗、闫海亮 |
| 绘制单位 | 深圳大学师范学院教育信息技术系、深圳大学师范学院教育信息技术系、深圳大学师范学院教育信息技术系、深圳大学师范学院教育信息技术系、深圳大学师范学院教育信息技术系 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}