《表2 大样本的分类结果比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
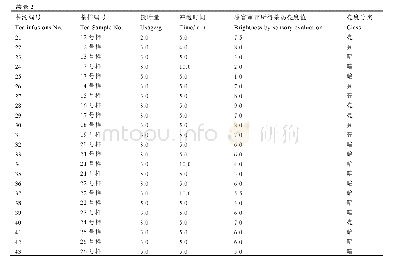
考虑到以上实验样本数据较少,结果可能不具有代表性,而DBN模型的优势又在于样本越大分类精确度越高.因此,我们引入了更具有代表性的大样本,样本总数为30000条光谱数据,维度为3909,分别为F、G、K型.值得注意的是,除对数据进行归一化处理以外,未进行其他预处理过程,且未限制光谱的信噪比值,样本标签分别为1、2、3,且在实验中将样本分为训练集和测试集,其中训练集27000条光谱,测试集3000条光谱.此外,Wang等[13]采用深度神经网络对同样F、G、K 3种类型恒星光谱的分类结果进行比较,样本为30000条,对光谱信噪比没有作限制.文章采用深度神经网络分类模型,节点设计为721-400-800-1200-2000-3,即有4个隐含层的分类器模型.可见在光谱数据保留721个特征的基础上基于伪逆学习算法对光谱进行分类实验,分类精确率为0.819.本实验同样采用深度学习模型,但与其不同的是深度信念网络结构由受限玻尔兹曼机堆叠而成,不需要对光谱进行降维,应用该模型对高维光谱数据的特征分层学习能力,尽可能保留有效特征以提升分类精确度.基于以上模型进行分类实验,并将所得结果同样在TOPCAT中与GAIA数据交叉,得到的颜色-星等图如图6所示,且将分类精确度与文献[11]进行比较,结果见表2(注:PILDNN是指基于伪逆学习算法的深度神经网络,PILDNN*是指将每条光谱作为输入向量时分为4个阶段并基于伪逆学习算法的深度神经网络).
| 图表编号 | XD0043002400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.01 |
| 作者 | 许婷婷、马晨晔、张静敏、周卫红 |
| 绘制单位 | 云南民族大学数学与计算机科学学院、云南农业职业技术学院经济管理学院、云南民族大学数学与计算机科学学院、云南民族大学数学与计算机科学学院、中国科学院天体结构与演化重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}