《表9 3种模型聚类算法效果比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
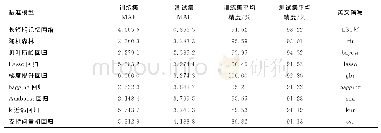
表9记录了3种聚类算法的轮廓系数、精确率Precision、召回率Recall和准确率Acc指标。轮廓系数结合内聚度和分离度两方面因素,评价了分类算法在分类效果上的优劣,其取值一般在[-1,1]之间,轮廓系数越接近1,表明聚类效果越好越合理;轮廓系数越接近-1,表明聚类结果越不合理,可能某个样本应该聚类到另外的簇上;如果轮廓系数接近0,则表明该分类样本可能在两个簇的边界上。从表9可以看出,EM聚类的轮廓系数大于K-means聚类和谱聚类,更接近1,表明EM聚类算法的聚类合理性更强,不同类别的区分更加明显。精确率、准确率和召回率分别表现了聚类算法的分类精确度(分好的类别中正确分类的样本占该类别的比例)、分类正确度(分类正确的样本数占总正确样本数的比例)和分类识别度(分类正确的样本数占总样本数的比例),是常用的聚类算法的评价指标,基本全面评价了一个算法的分类性能。表中EM聚类算法的精确率为91.78%、准确率为98.51%,召回率和谱聚类算法相等,均为77.01%;而K-means聚类算法的各项指标均远低于其他两种算法。在实践中,企业在识别出领先用户后需要进一步跟进沟通,并投入大量的人力和时间成本,如果识别模型错将非领先用户识别为领先用户,则会对企业造成一定的资源浪费,因此模型的精确率比召回率更重要。EM聚类算法的召回率较低,但是精确率超过了90%,因此EM聚类算法具有实用价值。综上所述,在领先用户识别研究中,EM聚类算法表现最好,有两项指标表现最优,谱聚类算法其次,K-means聚类算法效果不佳。
| 图表编号 | XD003770900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 曾庆丰、郭倩、张岚岚、曹昶琦 |
| 绘制单位 | 上海财经大学信息管理与工程学院、上海财经大学信息管理与工程学院、上海财经大学信息管理与工程学院、上海财经大学信息管理与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |

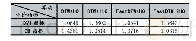


{kind=link}