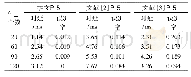
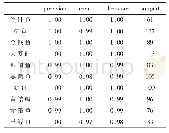
《表2 数值实验结果:基于选择性抽样的SVM增量学习算法的泛化性能研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于选择性抽样的SVM增量学习算法的泛化性能研究》
实验结果如表2所示,其中表的第二列为“数字/数字”,如数据集Skin中的10/8000,表示数据集Skin增量10次(10个子集),每次增量的样本数为8000;20/5000则表示数据集Skin增量20次(20个子集),每次增量的样本数为5000;为充分的表明基于选择性抽样的SVM增量学习算法的泛化能力,实验分别从错误分类率,支持向量个数,抽样与训练总时间三个方面对比基于选择性抽样的SVM增量学习算法和基于随机抽样的SVM增量学习算法。
| 图表编号 | XD0036351500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.25 |
| 作者 | 余炎、徐婕、陈前、杨艳 |
| 绘制单位 | 湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、武汉晴川学院计算机科学学院 |
| 更多格式 | 高清、无水印(增值服务) |


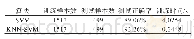

{kind=link}