《表2 混淆矩阵:不平衡数据挖掘方法综述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在传统的模型评估中,人们往往使用准确率和错误率来评估模型。但是在不平衡的数据中,少数类和多数类所占样本空间比例是不同的,一般地,少数类在样本空间中只有很少的一部分。例如,乳房X线照片的像素中可能会有癌细胞像素。而典型的乳房X线照片数据集中可能包含98%的正常像素和2%的异常像素,如果采用准确率来进行模型的评估,那么当模型将所有的像素预测为正常像素,那么正确率是98%,显然正确率作为评估标准是不合适的。因此,为了解决传统评价指标存在的缺陷,很多学者通常在研究不平衡数据挖掘时使用以下指标。在介绍这些评价指标前,本文先介绍一个概念——混淆矩阵[76]。对于二分类问题,其混淆矩阵如表2所示,TP、TN、FP和FN分别表示将正样本正确分类的数量,负样本正确分类的数量,负样本预测成正样本的数量以及正样本分类成负样本的数量;PC表示样本空间中真实类别为正样本的数量;NC表示样本空间中真实类别为负样本的数量。接下来,将对常用的指标进行介绍。
| 图表编号 | XD0035438000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.15 |
| 作者 | 向鸿鑫、杨云 |
| 绘制单位 | 云南大学软件学院、云南大学软件学院、昆明市数据科学与智能计算重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



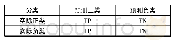

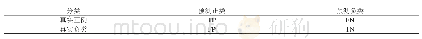
{kind=link}