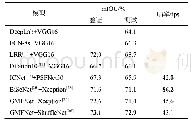
《表6 在CamVid、KITTI、JLUData测试集上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
CamVid、KITTI、JLUData都是道路街景数据集,且3个数据集分类种类比较相似,实验时,将这3个数据集统一处理成11分类(不包含“未知”分类)分别进行训练,实验结果如表6所示。从表6可以看出,在3个数据集上,RT-SegNet在精度上都比原始SegNet有显著提高。整体上,与SegNet相比,在CamVid、KITTI和JLUData数据集上,RT-SegNet在全局正确率上分别提升了11.3%、8.8%和11.6%;在类别平均正确率上分别提升了9.5%、12.9%和4.7%;在平均交叉联合度量上分别提升了5.3%、14.6%和6.8%。局部上,在CamVid数据集上,RT-SegNet在11个分类中有9个分类的分类正确率得到了提升,其中,杆、行人和自行车3个分类效果显著,正确率提升超过10%。在KITTI数据集上,RT-SegNet在11分类中的10个分类取得了更高的正确率,其中杆、交通标识、栅栏和自行车4个分类效果显著,正确率提升超过10%。在JLUData数据集上,RT-SegNet在11个分类中的9个分类提升了效果,其中,杆和自行车两个分类中效果显著,正确率提升都超过10%。3个数据集上,杆和自行车的分割效果都得到了超过10%的显著提升,表明RT-SegNet对占比小的分类具有较好的分割效果,分割更加精细。这与其特殊的结构设计是分不开的。特别地,在JLUData数据集上,“交通标识”这个分类不管是SegNet模型还是RT-SegNet模型都正确率极低,这与数据集本身的特点有关系。JLUData采集的是吉林大学校园街景,交通标识极少,数据集中最大的分类“路”的像素数量是“交通标识”像素数量的约5216倍,样本数量不足和这种极端的数据不平衡造成很难学习到“交通标识”的特征进行分类。在CamVid和JLUData数据集上的表现如图7、图8所示。
| 图表编号 | XD0035200600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 徐谦、李颖、王刚 |
| 绘制单位 | 吉林大学计算机科学与技术学院、吉林大学符号计算与知识工程教育部重点实验室、吉林大学计算机科学与技术学院、吉林大学符号计算与知识工程教育部重点实验室、吉林大学计算机科学与技术学院、吉林大学符号计算与知识工程教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}