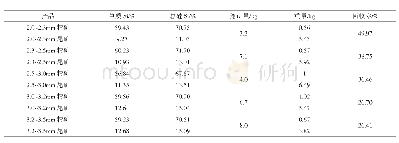
《表3 实验结果Tab.3 Experimental results》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《融合手工特征与双向LSTM结构的中文分词方法研究》
%
研究中选择使用F1值作为评价指标,实验结果详见表3。根据实验结果,融合手工特征和双向LSTM结构的方法取得了最优的效果,且相比其余2种方法提升明显。LTP作为传统中文分词方法的代表,在开发集和测试集上均取得了不错的效果,但是其在测试集上的F1值相比在开发集上低0.13个百分点,高于Uni-Bi-LSTM的0.11和All-Bi-LSTM的0.07,这表明在此数据集上基于Bi-LSTM的方法泛化能力更强。仅使用unigram特征的Uni-BiLSTM方法效果最差,相比All-Bi-LSTM在开发集上低1.65个百分点,测试集上低1.69个百分点。这表明仅是通过双向LSTM结构去自动学习输入中的特征还是不够的,引入手工特征能够显著提升模型效果。最后,同样基于手工特征,使用Bi-LSTM结构的All-Bi-LSTM方法比使用结构化感知器的LTP效果优异,在开发集和测试集上分别高0.28和0.34个百分点,这说明Bi-LSTM结构的特征组合能力更加强大。
| 图表编号 | XD0030168100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 徐伟、车万翔、刘挺 |
| 绘制单位 | 哈尔滨工业大学计算机科学与技术学院、哈尔滨工业大学计算机科学与技术学院、哈尔滨工业大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}