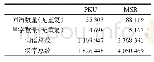
《表1 中文分词数据集详情Tab.1 The detail of Chinese word segmentation data set》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《融合手工特征与双向LSTM结构的中文分词方法研究》
在本次实验中采用的数据集为人民日报1998年上半年数据(约30万行、七百万词)和微博数据(约五万七千行、一百万词)的合并集,具体训练集、开发集和测试集信息可见表1。该数据集规模较大,能够充分发挥深度神经网络的能力。
| 图表编号 | XD0030168200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 徐伟、车万翔、刘挺 |
| 绘制单位 | 哈尔滨工业大学计算机科学与技术学院、哈尔滨工业大学计算机科学与技术学院、哈尔滨工业大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}