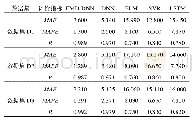
《表1 预测模型在外部测试集上的预测性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在该算例中,首先建立IML模型。将Keller数据库[19]中的气味数据划分成训练集、验证集和外部测试集。使用ANN构建的IMLs最终在外部测试集上的预测性能以回归系数R2[30]为指标进行表征,结果如表1所示。同时,还考虑采用支持向量机(support vector machine,SVM)、随机森林(random forest,RF)和多元线性模型(multiple linear regression,MLR)进行建模。各模型在外部数据集上的预测性能结果比较如表1所示。由表1可知,ANN模型的R2都在0.8以上,平均值为0.8807,预测效果较好。然而SVM、RF和MLR的R2平均值分别为0.2598、0.3018和0.2573,预测效果差。由此可以说明,使用ANN进行IMLs模型预测分子描述符是有优势的。
| 图表编号 | XD002562000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 王璐、毛海涛、张磊、刘琳琳、都健 |
| 绘制单位 | 大连理工大学化工学院化工系统工程研究所、大连理工大学化工学院化工系统工程研究所、大连理工大学化工学院化工系统工程研究所、大连理工大学化工学院化工系统工程研究所、大连理工大学化工学院化工系统工程研究所 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}