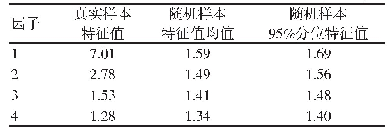
《表1 真实样本与随机数据样本的特征值比较(n=237)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
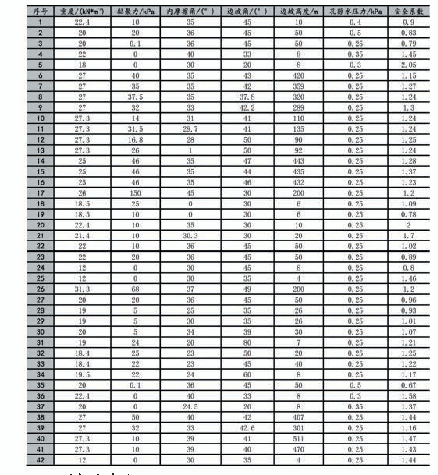
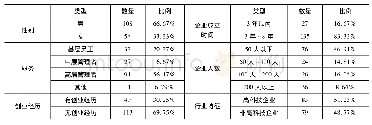
将样本数据随机分为a,b两组。对样本a数据(n=237)进行探索性因子分析(Exploratory Factor Analysis,EFA)。结果显示,KMO值为0.88,说明适合因子分析。特征值大于1的因子有4个,总方差贡献为57.29%。但第4个因子仅包括两个项目,只有5%的方差贡献,且这两个项目在第3个因子的载荷也比较高。平行分析(Parallel Analysis)是目前较为理想的确定因子数量的方法,通过比较真实数据特征值与随机数据特征值均值或95%百分位数来决定因子的取舍,当真实样本特质值大于随机数据特征值均值和95%百分位数时,说明这个因子是应该保留的[18]。平行分析结果显示,真实数据特征值在前三个因子均大于随机数据特征值的平均值和95%分位值,但在第四个因子真实样本特征值为1.28,小于随机样本特征值均值1.34和95%分位值1.40,说明保留3个因子更为合理,见表1与图1。
| 图表编号 | XD00217448900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.25 |
| 作者 | 彭嘉熙、陈立波、黄荷、孙浩、黄祺临、方鹏、苗丹民 |
| 绘制单位 | 成都大学师范学院、西南科技大学经济管理学院、空军军医大学军事医学心理学系、陆军勤务学院、陆军勤务学院、空军军医大学军事医学心理学系、空军军医大学军事医学心理学系 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}