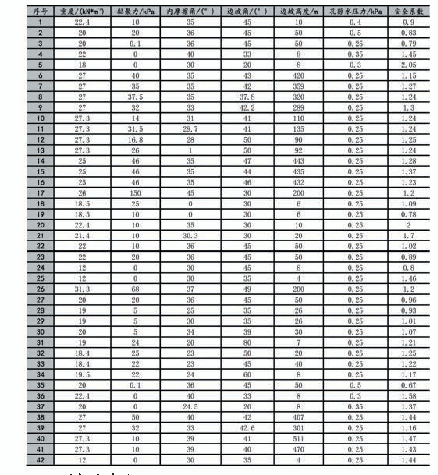
《表1 随机抽取样本算法:基于大数据分析的供热二次管网异常监测的算法比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
不放回随机抽样部分实现步骤是:首先,spark读取原数据集以为RDD抽象数据结构存入内存,计算数据集大小data_len并为每个样本添加索引,使用numpy库中的choice()函数从区间[0,data_len)以输入参数random_state为随机种子选取大小为n_estimators*max_sample的随机数列,使用broadcas()函数广播此数列,从添加索引后的数据集中筛选出索引在该随机数列中的样本,后续将使用筛选出的n_estimators*max_sample个样本构建孤立树。随机抽取样本算法见表1。
| 图表编号 | XD00122118500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 张庆峰、陈冬岩 |
| 绘制单位 | 山东大学控制科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}