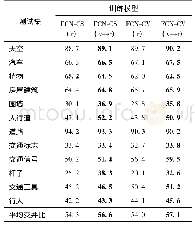
《表2 语义分割视觉模型训练阶段的性能(AP)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《面向智能驾驶的平行视觉感知:基本概念、框架与应用》
注:(v→r)表示先在虚拟图像集进行预训练,然后采用真实数据集进行微调,(r)表示直接在真实数据集进行训练。加粗字体为每行训练模型的最优值(同一测试地点)。
2)语义分割实验训练阶段。从北京中关村虚拟训练数据中随机挑选2 000幅(非雨雾条件)图像作为训练集用于FCN模型预训练。随后预训练模型分别在City Scapes和Cam Vid训练集上进行微调,最终得到模型命名为FCN-CS (v→r)和FCN-CV(v→r)。除此之外,实验不改变模型参数情况下,直接在City Scapes和Cam Vid训练集上进行训练,最终模型命名为FCN-CS(r)和FCN-CV(r)。随后,将上述4个模型分别在对应的测试集上进行测试,测试采用通用指标来评估语义分割结果。实验定量结果如表2所示,从表2中可以看出交通场景的语义分割实验经过虚拟图像预训练的模型比直接采用真实数据集的精度更高,特别是围墙、杆子精度提升效果,这是由于真实数据中缺少这些类别实例。
| 图表编号 | XD00215916000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.16 |
| 作者 | 李轩、王飞跃 |
| 绘制单位 | 鹏城实验室、北京理工大学自动化学院、中国科学院自动化研究所复杂系统管理与控制国家重点实验室、中国科学院自动化研究所复杂系统管理与控制国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}