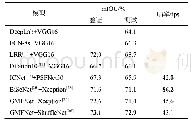
《表5 Xavier上的推理速度》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了验证网络在嵌入式平台的推理速度以及TensorRT的推理加速效果,本文在NVIDIA Jetson Xavier上进行了推理实验.Xavier的CPU采用8核ARM64架构,GPU采用512颗CUDA的Volta,支持FP32/FP16/INT8,20W功耗下单精度浮点性能1.3TFLOPS,Tensor核心性能20TOPs,解锁到30W后可达30TOPs.Cityscapes数据集上的图片像素尺寸为1024×2048,我们分别进行了以1倍,1/2倍,1/4倍尺寸为输入的网络在嵌入式平台Xavier推理速度测试实验,实验结果如表5所示.对于512×1024的输入图像,原网络在Xavier上的推理速度约为25 FPS,经过TensorRT加速后,推理速度达到了45FPS,加速比约为1.8,加速后的网络实现了嵌入式平台上的实时图像语义分割.
| 图表编号 | XD00212228900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 董建升、袁景凌、钟忺 |
| 绘制单位 | 武汉理工大学计算机科学与技术学院、武汉理工大学计算机科学与技术学院、武汉理工大学交通物联网湖北省重点实验室、武汉理工大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}