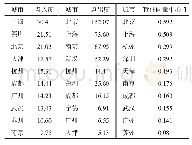
《表6 HubsRank和HITs算法枢纽节点出度前5的不重复前向节点数量分布表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
立足在迭代中降低前向节点投票能力的原则,HubsRank算法不重复的前向节点标号明显较多,占比更大。而且相比HITs算法,HubsRank算法高被引的权威节点大量集中于排名靠前的枢纽节点中,且基本覆盖了HITs算法发现的所有权威文献。另外,由于HITs算法在迭代前迭代次数难以预设的固有缺陷,HubsRank算法则可以在迭代前设置迭代次数,从而计算效率大大提高。通过数次迭代,就能够更早发现、更快覆盖到更多主题的高被引权威节点。后向延伸到更多排名,枢纽节点将会最大覆盖到“排序算法”领域的主题,形成最大覆盖的枢纽节点群。
| 图表编号 | XD00211138700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 李文静、刘向、谭琳洁、严婷婷 |
| 绘制单位 | 华中师范大学信息管理学院、华中师范大学信息管理学院、华中师范大学信息管理学院、华中师范大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}