《表1 并发原语功能说明:GPU数据库核心技术综述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
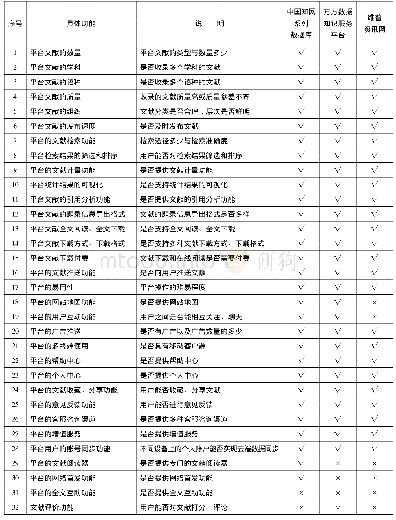
GDBMS系统普遍借鉴了GDB[17]分而治之的分层设计,将关系代数功能拆解为算子层(operator)和原语层(primitives)两部分,设计了一系列的适应GPU计算的数据并行原语(primitives),表1列出了大部分的GPU并发原语.在此基础之上,CoGaDB[10]通过调用GPU优化的高效数据结构库Thrust来实现相同的关系代数算法.这种使用NVIDIA官方程序库的方法具有性能高、升级成本低等优点,也是系统走向成熟的必经之路.此外,Diamos[41]等人于2012年提出了基于算法框架(algorithm skeleton)的处理行数据的关系代数原语实现,给我们提供了列数据之外的另一种解决方案.
| 图表编号 | XD00207341500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.01 |
| 作者 | 裴威、李战怀、潘巍 |
| 绘制单位 | 西北工业大学计算机学院、锦州医科大学、西北工业大学计算机学院、西北工业大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}