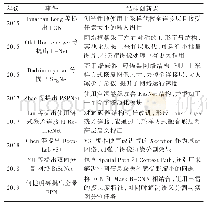
《表3 数据集汇总:基于深度学习的图像语义分割技术综述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
评估基于深度学习的图像语义分割算法性能的主要指标可归纳为:精确度、执行时间及内存占用等。处理速度或运行时间是重要的衡量指标,因为数据集一般较大,受到计算机硬件设施限制,更少的执行时间意味着更多的应用可能。内存是语义分割的另一个重要因素,不过内存在多数场景下是可以扩充的。精确度是最关键指标,图像分割中通常依据许多标准衡量算法精度。这些标准通常是像素精度及图像交并比衍变产生,如像素精度、均像素精度(Mean Pixel Accuracy,)、均交并比(Mean Intersection over Union,)等。像素精度是最简单的度量,用以标记正确像素占总像素的比例。均像素精度是类别内像素正确分类概率的平均值。均交并比是公认的算法评估标准,其计算两个集合的交集和并集之比,在语义分割领域中,真实值和预测值就是两个集合的体现。FCN网络的提出打破了传统分割方法,使用Caffe网络框架,在PASCAL VOC数据集上的分割精度(MIOU%)为62.2%。为解决FCN分割精度不高等问题,SegNet算法被提出,其使用Caffe网络框架,在CamVid数据集上的分割精度为60.1%。随后RefineNet出现,使用Pytorch网络框架,在PASCAL VOC数据集上的分割精度为83.4%。PSPNet提出金字塔模块,使用TensorFlow网络框架,在PASCAL VOC数据集上的分割精度为85.4%。BiSeNet和全景FCN的提出使语义分割算法更加完善,它们在Cityscapes数据集上的分割精度分别达68.4%和79%。上述数据集汇总如表3所示,网络框架汇总如表4所示。
| 图表编号 | XD00207305300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.15 |
| 作者 | 卢旭、刘钊 |
| 绘制单位 | 广东技术师范大学计算机科学学院、广东技术师范大学计算机科学学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}