《表1 材料识别数据库:基于计算机视觉的材料感知技术综述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
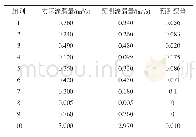
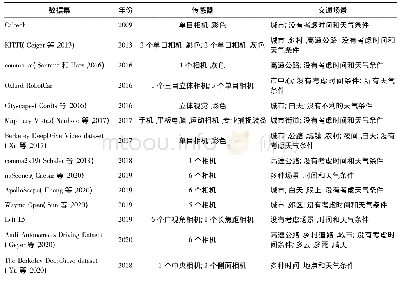
尽管目前在目标识别方面,计算机视觉的识别成功率超越了人类[28,29],但是在材料识别方面,计算机视觉的表现远远比不上人类。有研究者认为,材料识别落后于物体识别的原因或许是因为缺少训练的数据库[26]。表1为近些年研究者创建的用于材料识别的数据库,其中CURe T和KTH-TIPS这两个数据库主要用于材料属性和参数估计。最初,一些研究人员采用人工选取的特征(如颜色、SIFT等)提供给标准分类器,基于这种材料识别系统,Sharan等人[4,30]通过网上下载1 000张图片(包含10种材料,每种材料包含100张图片)建立Flickr material database(FMD)。这个数据库成为人类和计算机识别材料的经典数据库。通过志愿者参与实验,Sharan及其同事发现,人类可以在短短的40 ms的时间内从假材料中精确地识别出真实材料[31~33]。根据人类材料识别经验,Sharan等人[34]在图片中提取出人类在材料识别过程中运用到的低级和中级视觉特征,并提供给SVM分类器,识别正确率达到57%;Liu等人[35]利用FMD在贝叶斯框架下结合图片的低级和中级特征提出增强LDA模型,实验识别率达到46%;Badami[36]通过SVM分类器达到53.1%。接着更多的模型趋向采用CNN自动提取特征,Schwartz等人[37,38]结合无监督学习和手工选取的特征能达到48.9%准确率。为了弥补像物体识别中ImageNet[39]那样的带有标签图片的数据库缺失,Wieschollek等人[40]建立了谷歌材料数据库(GMD),并用迁移学习法在数据库GMD和FMD中进行实验,识别率分别达到74%和64%。Bell等人[41]利用众包技术建立了自然环境下的材料数据库,该数据库由含有300万张手工标记区图片组成23种材料。毫无疑问,随着材料识别数据库的建立并完善,必将促进材料视觉感知的发展。
| 图表编号 | XD0090316700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 邹凌云、伍世虔、方红萍、黄志开 |
| 绘制单位 | 武汉科技大学冶金装备及其控制教育部重点实验室、南昌工程学院机械与电气工程学院、武汉科技大学冶金装备及其控制教育部重点实验室、武汉科技大学冶金自动化与检测技术教育部工程研究中心、南昌工程学院机械与电气工程学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}