《表4 FasterR-CNN和ResNeXt性能对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
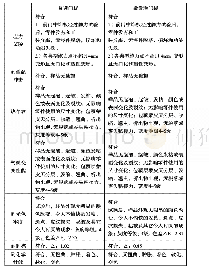
卷积神经网络是目前比较通用的图像特征提取方法,目前,大部分的图像任务大多基于一个效果较好的卷积网络比如ResNet-101[65]提取图像表征,然后在一个具体任务上进行应用.BERT在处理文本任务时,其输入的信息都是词或者字,是一个小的语义单元,将整张图片向量作为输入,将无法很好地学习视觉语义单元信息,所以一般对图片进行目标检测操作,然后将检测后的结果进行处理,然后作为一个语义单元作为输入.表4中展示了Unicode-VL模型在句子检索和图像检索任务中使用ResNeXt[66]模型和FasterR-CNN[67]模型提取检测框的差别.
| 图表编号 | XD00207321900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.01 |
| 作者 | 杜鹏飞、李小勇、高雅丽 |
| 绘制单位 | 可信分布式计算与服务教育部重点实验室(北京邮电大学)、北京邮电大学网络空间安全学院、可信分布式计算与服务教育部重点实验室(北京邮电大学)、北京邮电大学网络空间安全学院、可信分布式计算与服务教育部重点实验室(北京邮电大学)、北京邮电大学网络空间安全学院 |
| 更多格式 | 高清、无水印(增值服务) |
![表4 本文方法与文献[4]和文献[9]的性能对比](http://bookimg.mtoou.info/tubiao/gif/DZYX202009010_09300.gif)




{kind=link}