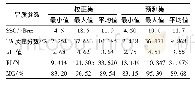
《表1 生长期红提样品利用KS算法划分样本集的数据统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《便携式红提葡萄多品质可见/近红外检测仪设计与试验》
KS(Kennard Stone)算法作为常用的样本划分算法,利用变量空间之间的相对欧氏距离找出样品集中差异较大的样品选入校正集,其余相近的样品选入预测集。试验中每个指标共采集了360份红提样本,按照3∶1比例利用KS算法划分为270个校正集样本,90个预测集样本。从表1中可以看出,SSC的分布范围为4.5~19.0°Brix,校正集和预测集的平均值分别为11.9、11.7°Brix;总酸质量分数分布范围为2.254%~37.663%,校正集和预测集的平均值分别为10.185%、9.868%;p H值分布范围为2.68~4.62,校正集和预测集的平均值分别为3.64、3.55;硬度分布范围为9.414~121.305 N,校正集和预测集的平均值分别为33.620、31.975 N;含水率分布范围为83.15%~96.52%,校正集和预测集的平均值分别为89.54%、89.68%。表明数据的分布范围较广,通过KS划分的数据集分布较为合理,可提高预测模型的稳定性。
| 图表编号 | XD00206377700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.25 |
| 作者 | 高升、王巧华、施行、李庆旭 |
| 绘制单位 | 华中农业大学工学院、农业农村部长江中下游农业装备重点实验室、华中农业大学工学院、农业农村部长江中下游农业装备重点实验室、华中农业大学工学院、农业农村部长江中下游农业装备重点实验室、华中农业大学工学院、农业农村部长江中下游农业装备重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}