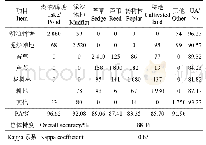
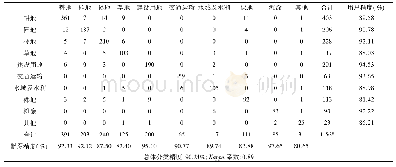
《表1 湿地分类混淆矩阵及精度》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《采用全卷积神经网络与Stacking算法的湿地分类方法》
注:土地利用类型对应数值为其列所在类别被分为行所在类别的像元数。UA为生产者精度,PA为用户精度。下同。
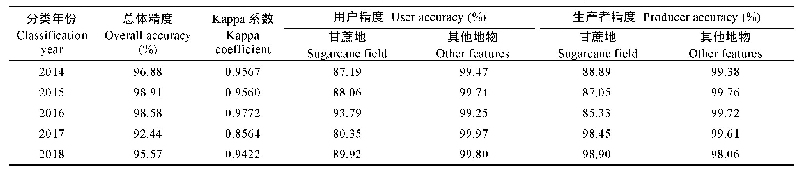
基于本文方法提取湿地信息的总体分类精度为88.16%,Kappa系数为0.85。该方法能够有效地提取大部分湿地类型,其中,湖泊/库塘、泥沙滩地、苔草的生产者精度与用户精度均在90%左右(表1),但对芦苇和杨树林容易形成错分,主要原因在于两者在生长季的部分时段具有相似的光谱特征,难以用单时相的遥感影像进行区分(182个杨树林像元被分为芦苇,141个芦苇像元被分为杨树林)。同时,苔草与芦苇、杨树林及耕地,芦苇与耕地,湖泊与泥沙及其他类之间也存在着错分的情况(125个芦苇像元被分为苔草,158个苔草像元被分为芦苇;137个耕地像元被分为杨树林,67个杨树林像元被分为耕地)。植被之间的误分情况主要由于洞庭湖湿地植被多样性丰富,易形成混合像元,单时相GF-6遥感数据难以将其准确区分。5月份春汛使得流入洞庭湖的水泥沙含量较多,因此造成了部分湖泊/库塘与泥沙滩地之间的错误分类。另外,该时期部分耕地未种植农作物或经济作物,使得耕地的光谱特征与泥沙滩地类型,这是造成两者错分的主要原因。
| 图表编号 | XD00206348400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.01 |
| 作者 | 张猛、林辉、龙湘仁 |
| 绘制单位 | 中南林业科技大学林业遥感信息工程研究中心、中南林业科技大学林业遥感大数据与生态安全湖南省重点实验室、中南林业科技大学南方森林资源经营与监测国家林业与草原局重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}