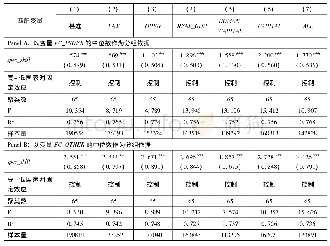
《表7 倾向得分匹配估计结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
资料来源:根据联合国商品贸易统计数据、全球竞争力指数历史数据、佩恩表数据、世界银行全球治理指数和世界发展指标数据、美国制造业产业数据、Tang (2012)的研究数据计算得到。
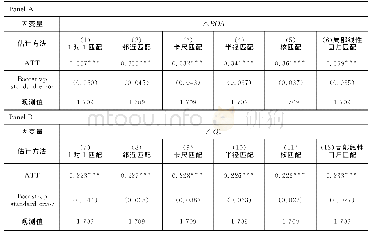
然而,上文基于模型(9)进行估计可能面临的一个问题是,在利用工具变量FC_INDEX和FC_OTHER的中位数区分后,高、低劳动保护程度国家可能在诸如法律制度、金融发展、收入水平、要素禀赋等方面存在差异,从而导致估计出的比较优势差异并不是源于劳动保护程度不同,致使表7第(1)列的估计结果存在偏误。为此,我们基于Rosenbaum&Rubin (1985)倾向得分匹配的思路,根据法律规则指数、物质资本丰裕度等匹配变量,对高、低劳动保护程度国家进行重新配对,形成新的样本数据;然后,利用匹配后的样本数据对模型(9)进行再估计,从而达到减少法律制度、要素禀赋等因素差异对估计结果造成干扰的目的。具体匹配过程分为两步(1):第一步,采用与上文相同的思路,利用工具变量FC_INDEX的中位数将所有国家分为两组,将FC_INDEX高于中位数的国家定义为高劳动保护程度国家,变量H_dum取1,否则,H_dum取0,为低劳动保护程度国家;第二步,根据匹配变量B (包括各国法律规则指数LAW、各国贸易开放程度OPEN(2)、各国收入水平REAL_GDP、各国人力资本水平HUMAN_CAPITAL、物质资本丰裕度CAPITAL),建立二元选择模型Pr (H_dumc)=Φ(Bc),采用Logit模型逐年估计各国的倾向得分(score);最后,根据倾向得分估计结果,采用最近邻匹配法(nearest neighbor matching),以1:3的比例进行匹配,从而形成匹配后的样本数据。
| 图表编号 | XD00204507500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.15 |
| 作者 | 李波、杨先明、李善萍 |
| 绘制单位 | 云南大学经济学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}