《表2 DUC2001中对比实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
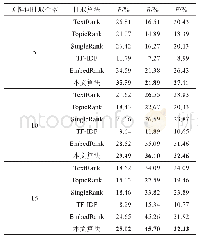
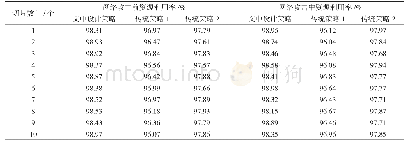
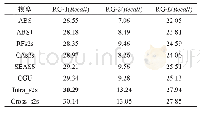
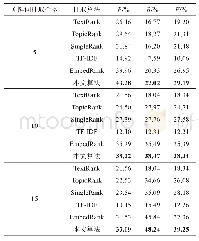
为了证明本文算法的有效性,在两个公开数据集Hulth2003和DUC2001上,与目前主流关键词抽取算法进行了对比实验。由于本文算法是一种基于图的无监督方法,因此选取了3个基于图的经典抽取算法Text Rank[12]、Topic Rank[21]、Single Rank[13]。另外,还选取了一个基于统计的经典算法TF-IDF,以及一个基于Embedding思想的Embed Rank算法[29],实验中Text Rank、Single Rank以及本文算法中图的节点均为名词或形容词,Topic Rank的图中节点为主题簇,实验中选择每个簇中最中心的词语作为关键词,本文算法的阻尼系数α取0.2,词共现窗口设置为1,详细的实验结果如表1和表2所示,详细列出了抽取的关键词个数分别为5、10、15时,各算法的抽取结果。
| 图表编号 | XD00204318200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.01 |
| 作者 | 祖弦、谢飞、刘啸剑 |
| 绘制单位 | 合肥师范学院计算机学院、合肥师范学院计算机学院、合肥工业大学计算机与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}