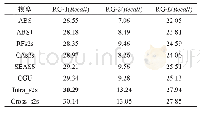
《表2 Gizaword与DUC2004英文测试上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表2给出了近些年神经网络模型在Gizaword和DUC2004上所展现的实验效果以及基准系统Transformer模型和使用了本文中所提出的模型结构的实验结果.需要注意一点,对于Gizaword数据所采用的评估指标是基于F值(正确率(P)与召回率(R)的加权调和平均)的ROUGE-1(R-1)、ROUGE-2(R-2)、ROUGE-L(R-L),而DUC数据的则是基于R.表中列举了3个在抽象文本摘要上的最新成果:Gehring等[5]提出的完全基于卷积构成ConvS2S框架的结果;在此结构的基础上,Edunov等[11]和Wang等[9]分别从结构损失(CNN+结构损失)和强化学习(CNN强化)的角度改进模型的结果.表格中“—”表示文章中并未提及此类数据的实验结果.最后两行分别是Transformer基准系统以及本文方法(Transfomer+冗余序列)的实验结果.从表中可以发现,Transformer基准系统在英文测试集上的表现十分显著.在Gigaword数据上,相较于其他系统,Transformer基准系统的R-1,R-2和R-L得分均最高;并且在添加了冗余序列的信息之后,系统性能得到了进一步地提升.相对于Transformer基准系统,本文中的方法在每种评估指标上的得分均增加了0.7个百分点.在DUC2004数据上,该方法也在基准系统上获得了一定的提升.整体上讲,该方法能够获得更加精准、质量更高的摘要文本.
| 图表编号 | XD009204100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.28 |
| 作者 | 俞鸿飞、王坤、殷明明、段湘煜、张民 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}