《表1 Gigaword和DUC2004数据集统计结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
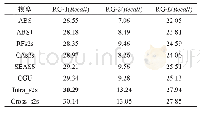
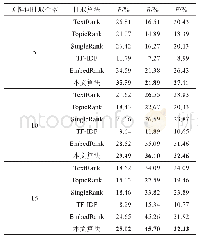
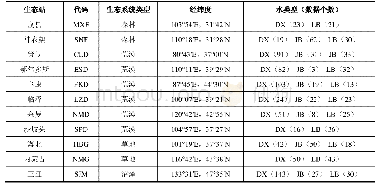
本文使用文本摘要领域常用的英文数据集Gigaword作为训练集,采用与Nallapati[7]相同的预处理脚本(https://github.com/facebook/NAMAS)对数据集进行预处理,分别得到380万和18.9万的训练集和开发集,每个训练样本包含一对输入文本和摘要句。与前人的研究工作相同,本文对数据进行标准化处理,包括数据集所有单词全部转小写,将所有数字替换为#,将语料中出现次数小于5次的单词替换为UNK标识等。为了便于对模型性能进行评价,与所有的基准模型一样,本文从18.9万开发集中随机选择8 000条作为开发集,选择2 000条数据作为测试集,然后筛选去除测试集中原文本长度小于5的句子,最后得到1 951条数据作为测试集。为了验证模型的泛化能力,选择DUC2004作为测试集。DUC2004数据集仅包含500条文本,每个输入文本均对应4条标准摘要句。表1列出了Gigaword和DUC2004两个数据集具体的统计信息。
| 图表编号 | XD00223470100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.01 |
| 作者 | 黄于欣、余正涛、相艳、高盛祥、郭军军 |
| 绘制单位 | 昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}