《表1 不同方法的性能对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
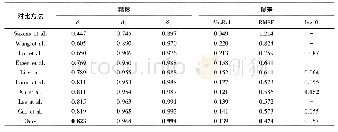
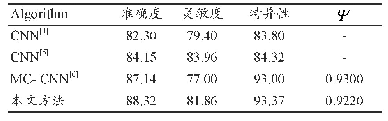
数据重构能力是VAE模型的重要性能指标,式(12)的损失越低说明模型为正确音符分配的概率越高。本文额外训练了四个生成模型进行对比,分别是Piano Genie[11]、Music VAE[16]、RNN语言模型Seq2Seq以及基本的VAE。Seq2Seq通过前16个音符预测后16个音符;Piano Genie仅通过轮廓标签序列来重构旋律样本;VAE和Music VAE仅用潜变量编码整个旋律。这些模型都利用和本文模型CCMG-VAE一致的LSTM构建,且隐藏层向量宽度也保持一致。通过相同训练参数设置以及优化算法进行训练,所得的数据重构损失曲线如图6所示。图6中,VAE最终收敛结果最差;Music VAE利用层次结构缓解后验塌陷,性能略优于VAE;Seq2Seq的损失曲线最不稳定;CCMG-VAE最终的重构损失最低,相比Piano Genie曲线更稳定。本文还测试了所有模型在整个训练集与测试集上的平均重构损失、重构音符正确率,如表1所示。
| 图表编号 | XD00202127400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.05 |
| 作者 | 范纯龙、张振鑫、丁三军、滕一平、王翼新 |
| 绘制单位 | 沈阳航空航天大学计算机学院、辽宁省大规模分布式系统实验室、沈阳航空航天大学计算机学院、沈阳飞机设计研究所、沈阳航空航天大学计算机学院、辽宁省大规模分布式系统实验室、沈阳航空航天大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}