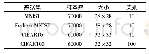
《表1 数据集相关信息:基于ML loss的SVM分类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
使用MNIST、Fashion-MNIST、CIFAR10和CIFAR100数据集和hinge SVM等多个SVM模型进行分类实验[13],数据集的相关信息如表1所示。每个数据集中均加入噪声,噪声比例为0.1、0.2和0.3。MNIST和Fashion-MNIST数据集均有60 000个训练集和10 000个测试集,分成600个训练批,每批100个样本,CIFAR10和CIFAR100均有50 000个训练集和10 000个测试集,训练集分成500个训练批,每批为100个样本,使用7折交叉验证,SVM均使用高斯核函数。
| 图表编号 | XD00202122000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.05 |
| 作者 | 徐龙飞、郁进明 |
| 绘制单位 | 东华大学信息科学与技术学院、东华大学信息科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}