《表1 两个数据集的统计数据》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:#表示数量。
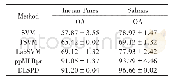
本文采用的数据集是Movie Lens-20M和Last.FM,其中Movie Lens-20M是在电影推荐中广泛使用的基准数据集,由电影网站上1 000多万个明确的评分组成。Last.FM是从last.fm在线音乐系统收集的音乐收听数据集。本文使用DBpedia本体知识库[18]为每个数据集构建知识图谱,将每个数据集的用户、项目和它们的属性值映射链接到相应的实体,每个数据集的用户属性、项目属性和用户的行为属性视为关系。此外,还利用数据集中的用户ID、性别、年龄和职业信息来构建三元组,例如(u1,gender,female)。两个数据集的统计数据如表1所示。对于每个数据集,随机选择每个用户80%的交互历史来构成训练集,其余数据集作为测试集。从训练集中随机选择10%的交互作为验证集来调整超参数。将每一个观察到的用户项目交互视为正样本,然后执行负抽样策略,将其与一个负样本进行匹配。
| 图表编号 | XD00202106100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.05 |
| 作者 | 荣沛、苏凡军 |
| 绘制单位 | 上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}