《表6 不同基于FPGA的CNN加速器的比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
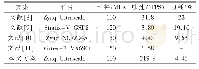
表6列出了3类基于FPGA的CNN加速器,为了方便比较,本文将其分别命名为加速器A[22]、加速器B[23]和加速器C[24]。加速器A、B的目标器件是XC7VX690T,其PL端拥有3 600个DSP,比本文的目标器件XCZU9EG多出1 080个DSP,但加速器A、B的算力远低于本文的加速器,主要有两个原因:首先是它们的加速器架构未充分利用PL端的DSP资源;其次是因为它们利用的数据类型位宽较宽,加速器A的特征数据为16 bit整型、权重数据为8 bit整型(在表5中表示为INT16/8),加速器B的特征数据和权重数据均为16 bit整型,均大于本文所采用的位宽。加速器C所使用的器件为XCVU440,拥有2 880个DSP,但其算力只有本文加速器的42.89%。比较发现,本文提出的CNN加速器架构可充分利用PL端的DSP资源,并能达到较高水平的算力。
| 图表编号 | XD00201823500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.10 |
| 作者 | 王晓峰、蒋彭龙、周辉、赵雄波 |
| 绘制单位 | 北京航天自动控制研究所、宇航智能控制技术国家级重点实验室、北京航天自动控制研究所、宇航智能控制技术国家级重点实验室、北京航天自动控制研究所、宇航智能控制技术国家级重点实验室、北京航天自动控制研究所、宇航智能控制技术国家级重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}