《表4 对比实验结果:基于Apex帧光流和卷积自编码器的微表情识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为进一步分析Apex-OFCAE方法在不同数据集中的性能差异,绘制了融合数据集和3个单独数据集分类结果的混淆矩阵。如图6所示,(a)~(d)分别表示融合数据集、CASME II、SAMM和SMIC的混淆矩阵。纵坐标表示微表情的真实标签,横坐标表示预测的分类标签,数值代表各个类别预测概率。例如,融合数据集中0.82代表实际类别是“消极”并被正确预测为“消极”的概率;0.30表示实际类别为“积极”但是被预测为“消极”的概率。可以看出不少“积极”或者“惊讶”类别被错误地预测为“消极”,原因是类别不平衡,“消极”样本总数超过一半(250/442),因此分类结果偏向于“消极”类别。提出的方法在CASME II数据集上识别性能最好,SMIC数据集性能不好的原因是分辨率和帧率比较低,Apex帧的选取跟实际的Apex帧存在一定的误差。SAMM数据集中的问题是类别间样本数量不平衡,“惊讶”和“积极”的样本数量分别只占总量的10%和20%。因此,对于SMIC和SAMM数据集的识别还存在较大的挑战。
| 图表编号 | XD00201540800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.15 |
| 作者 | 温杰彬、杨文忠、马国祥、张志豪、李海磊 |
| 绘制单位 | 新疆大学信息科学与工程学院、新疆大学信息科学与工程学院、中国电子科学研究院社会安全风险感知与防控大数据应用国家工程实验室、新疆大学软件学院、新疆大学信息科学与工程学院、新疆大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



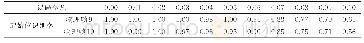

{kind=link}