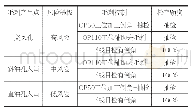
《表4 罪名决策分类结果(基于文本特征和法条特征的)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
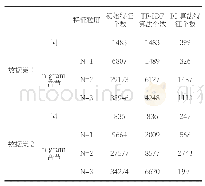
罪名的预测有两种情况,第一种是只用文本特征来进行罪名标签的预测,实验结果如表3所示。第二种情况是除了将文本特征作为分类输入外,还将预测的法条标签作为输入来进行罪名的预测,实验结果如表4所示。由表3看出,本文方法在六个指标上相比其他模型效果最好,说明将两种模型进行融合后的整体框架较单独的基于CNN的Text-CNN和GRU更为有效,由于结合了CNN和LSTM对案例文本进行编码,这样得到的文本特征不仅具有短时特征,更考虑了长时间依赖关系,这种更完整的文本表示无论是进行法条预测还是罪名预测均取得了较好的结果。CPM相比GRU模型在macro-F1上提高了6.7%,说明了attention机制作用于GRU的机制是有效的,更着重关注与标签相关的关键信息,这样的文本编码信息携带了决定性的信息,对最终的罪名预测是非常重要的。本文方法相比LJPVTP提高了2.2%,说明将BiLSTM直接取代最大池化层并且只采用单尺度特征,在降低运算量的同时也可取的较好的分类结果。
| 图表编号 | XD00198052700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.31 |
| 作者 | 崔斌、邹蕾、徐明月 |
| 绘制单位 | 北京京航计算通讯研究所信息工程事业部、北京京航计算通讯研究所信息工程事业部、北京京航计算通讯研究所信息工程事业部 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}