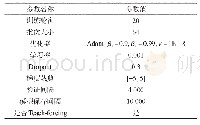
《表1 超参数和模型结构设置》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
首先采用结巴分词器对犯罪文本进行中文分词处理,然后利用word2vec模型训练词向量。使用预训练好的词向量得到犯罪文本的向量表示,其中词向量维度设为300。实验基于TensorFlow框架[11],具体参数设置如表1所示。迭代次数为10次,采用随机梯度下降法作为优化器进行训练。
| 图表编号 | XD00198052200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.31 |
| 作者 | 崔斌、邹蕾、徐明月 |
| 绘制单位 | 北京京航计算通讯研究所信息工程事业部、北京京航计算通讯研究所信息工程事业部、北京京航计算通讯研究所信息工程事业部 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}