《表2 模型超参数设置:利用层级交互注意力的文本摘要方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
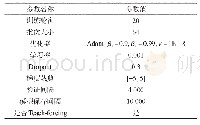
本文选择Pytorch框架进行开发,在NVIDIA P100上进行训练。编码器和解码器均选择3层的LSTM,其中编码器为双向LSTM,而解码器采用单向LSTM。编码器和解码器的隐状态均设置为512。为了减少模型的参数,设置编码器和解码器共享词嵌入层。词嵌入维度设置为512,本文不使用Word2vec、Glove、Bert等预训练词向量,而是对词嵌入层随机初始化。与Nallapati、Zhou等人不同[2,22],本文设置编解码器的词表的大小为50 000,未登录词使用UNK来替代。为了提高摘要的生成质量,本文在模型推断阶段使用Beam Search策略[35],Beam Size设置为12。其他训练超参数设置如表2所示。
| 图表编号 | XD00223469500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.01 |
| 作者 | 黄于欣、余正涛、相艳、高盛祥、郭军军 |
| 绘制单位 | 昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}