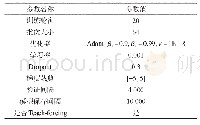
《表1 超参数设置:基于多空间混合注意力的图像描述生成方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文选用在MSCOCO caption数据集上验证算法的有效性。MSCOCO是微软公开的图像描述数据集,包含着82 783张训练集、40 504张验证集和40 775张测试集。相对于其他小规模的图像描述生成数据集,COCO caption数据集更有挑战力,也更加具有公信力,其中一张图片对应5句描述,由json格式提供。本文采取的验证模型优劣的方式分为两个步骤:先通过训练集和验证集在线下调节模型的参数,然后提交测试集的结果到服务器上获取对应指标的分数。最终的解码模型获取分为两轮,区别在于第一轮是对交叉熵损失函数进行优化,第二轮是通过策略梯度对模型进行调节。第一轮设置为学习率0.000 1,选用Adam优化器降低交叉熵损失,收敛至平稳后,再降低学习率,直至交叉熵损失无法进一步优化,最大迭代轮数为30。得到较稳定的交叉熵解码模型后,再使用策略梯度替换交叉熵损失函数,采取相同的超参数进行优化,两轮训练的总迭代周期为70。沿用Karpathy等[16]的数据集设置,分别使用5 000张图片用于线下的验证和测试。表1列出训练时候的超参数设置。词嵌入向量设为1 024,LSTM的隐藏层向量大小设置为1 024。为了防止过拟合对加入dropout,设为0.5。
| 图表编号 | XD00133817500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.10 |
| 作者 | 林贤早、刘俊、田胜、徐小康、姜涛 |
| 绘制单位 | 杭州电子科技大学通信信息传输与融合技术国防重点学科实验室、杭州电子科技大学通信信息传输与融合技术国防重点学科实验室、杭州电子科技大学通信信息传输与融合技术国防重点学科实验室、杭州电子科技大学通信信息传输与融合技术国防重点学科实验室、杭州电子科技大学通信信息传输与融合技术国防重点学科实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}