《表3 模型参数设置:上下文感知与层级注意力网络的文档分类方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
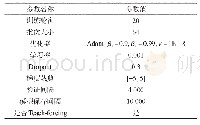
实验过程中模型的超参数在验证集上进行微调,而最终的算法性能比较在测试集中进行。本文中,GRU网络的单元个数设置为50,那么Bi-GRU网络生成的向量维数为100。随机初始化的单词上下文向量uw和句子上下文向量us的维度设置为100。对于模型的训练,将词嵌入的维度设置为100,采用大小为64的批处理,采用动量为0.9的随机梯度下降法(stochastic gradient descent,SGD)来训练所有的模型,并且在验证集上使用网格搜索来选择最佳学习率。此外,为了防止网络神经元出现共同适应性,本文还使用大小为0.5的dropout来随机丢弃网络中的神经元。经过多次调整,选取一组最优模型参数,如表3所示。
| 图表编号 | XD00204318400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.01 |
| 作者 | 任建华、李静、孟祥福 |
| 绘制单位 | 辽宁工程技术大学电子与信息工程学院、辽宁工程技术大学电子与信息工程学院、辽宁工程技术大学电子与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}