《表2 Reuters Corpus数据集上的实验结果对比分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
/%
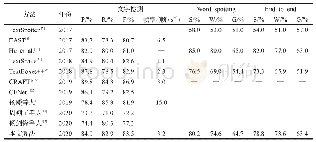
数据集质量对分类器的效果具有直接影响,复旦大学提供的文本分类语料库是一个严重不均衡的分类语料库,改进算法的优势可能体现得并不明显,因此在重复对比实验中采用了国际广泛应用的路透社语料库Reuters Corpus,并从中随机选取了五个类别,每一类别的训练集和测试集均为400和200篇。实验将本文L2KNN_W与LLKNN、KNN、Rocchio[22]、SVM[23]、NB[24]、Text CNN算法[21]进行对比,表2只显示了测试结果的平均值。从表2中可以明显看出,L2KNN_W算法的准确率比其他主流算法最低提升2.2%,最高提升13.26%;召回率虽低于SVM和LLKNN算法,但结果仍然是可以接受的。综合来看,改进后的算法在实验数据上比其他算法的表现效果较优,分类效果可以满足现有要求。
| 图表编号 | XD00198015700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.05 |
| 作者 | 齐斌、邹红霞、王宇 |
| 绘制单位 | 北京空间信息中继传输技术研究中心、航天工程大学航天信息学院、航天工程大学航天信息学院、航天工程大学航天信息学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}