《表4 中文蕴含语块-类型识别任务上各系统的性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
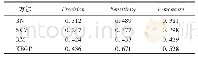
以上4个实验的输入均保持一致,仅在系统的模型结构部分不同.从表4看出,BERT(61.58%)在测试集上的表现优于ESIM(52.80%).这证实了BERT模型在蕴含语块-类型识别任务上的有效性,其使用更加灵活,更能学习上下文的关系,对前后语块联系密切的边界标注任务十分友好.BERT+Bi LSTM+CRF(62.06%)比Bi LSTM+CRF(50.92%)高11.14%,提升显著.而BERT+Bi LSTM+CRF(62.06%)只比BERT(61.58%)高0.48%,提升效果并不明显.在有BERT的情况下,将句对作为整体输入,加上Segment Label以区分前后句,使得BERT+Bi LSTM+CRF在句对标注任务上有更好的结果,然而Bi LSTM+CRF在其中作用有限.虽然Bi LSTM+CRF广泛应用在与命名实体识别相关的任务中,在单句标注任务上表现较好,但是本任务更关注句对之间的联合信息,Bi LSTM+CRF的实验效果在句对标注任务上不是很理想.
| 图表编号 | XD00193813900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.01 |
| 作者 | 于东、金天华、谢婉莹、张艺、荀恩东 |
| 绘制单位 | 北京语言大学信息科学学院、北京语言大学信息科学学院、北京语言大学信息科学学院、北京语言大学信息科学学院、北京语言大学信息科学学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}