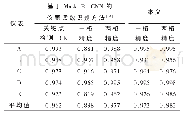
《表2 隐喻识别器在中文隐喻识别任务上的表现(%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
中文隐喻识别的结果如表2所示,各个评测指标最佳结果用加粗表示。在中文数据集上的实验结果和英文数据集类似,准确率和F1值最高可以提高8.9%和7.8%,M1(B,S)融合方式在TroFi_CN数据集上的综合表现最好,M2(B,S,W)融合方式在AN_CN数据集上表现最好。隐喻识别器在中文数据集上的各项测评指标比英文数据集要差一点,这是因为对英文数据集的翻译会造成部分语义信息的损失,且中文数据集数据处理上还有分词这一步骤,分词的正确率本身达不到百分之百,造成的误差会进一步影响到隐喻识别的效果。
| 图表编号 | XD00174895500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.25 |
| 作者 | 苏传东、黄孝喜、王荣波、谌志群、毛君钰、朱嘉莹、潘宇豪 |
| 绘制单位 | 杭州电子科技大学认知与智能计算研究所、杭州电子科技大学认知与智能计算研究所、杭州电子科技大学认知与智能计算研究所、杭州电子科技大学认知与智能计算研究所、杭州电子科技大学认知与智能计算研究所、杭州电子科技大学认知与智能计算研究所、杭州电子科技大学认知与智能计算研究所 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}